
type
status
date
slug
summary
tags
category
icon
password
Author
Featured
Featured
Published
Public
Public
背景
ControlNet可以用来很好的控制最终出图的效果,但是现在text2pose还没有特别高质量的办法,很多时候还是需要给一个预生成的数据集。那我有没有办法做一个高质量数据集,包含几百张poses(类似素描模特那样),这样对于绝大多数场景都能够直接拿来用了。一个自然的需求就是,我可不可以基于prompt的文字描写,自动找到最贴合的pose呢?
答案是可以的!虽然不敢保证所有情况的质量,但是已经很够用了。
下图是我用query 『fighting』从数据集中找出最接近的4张图片用作controlnet输入。
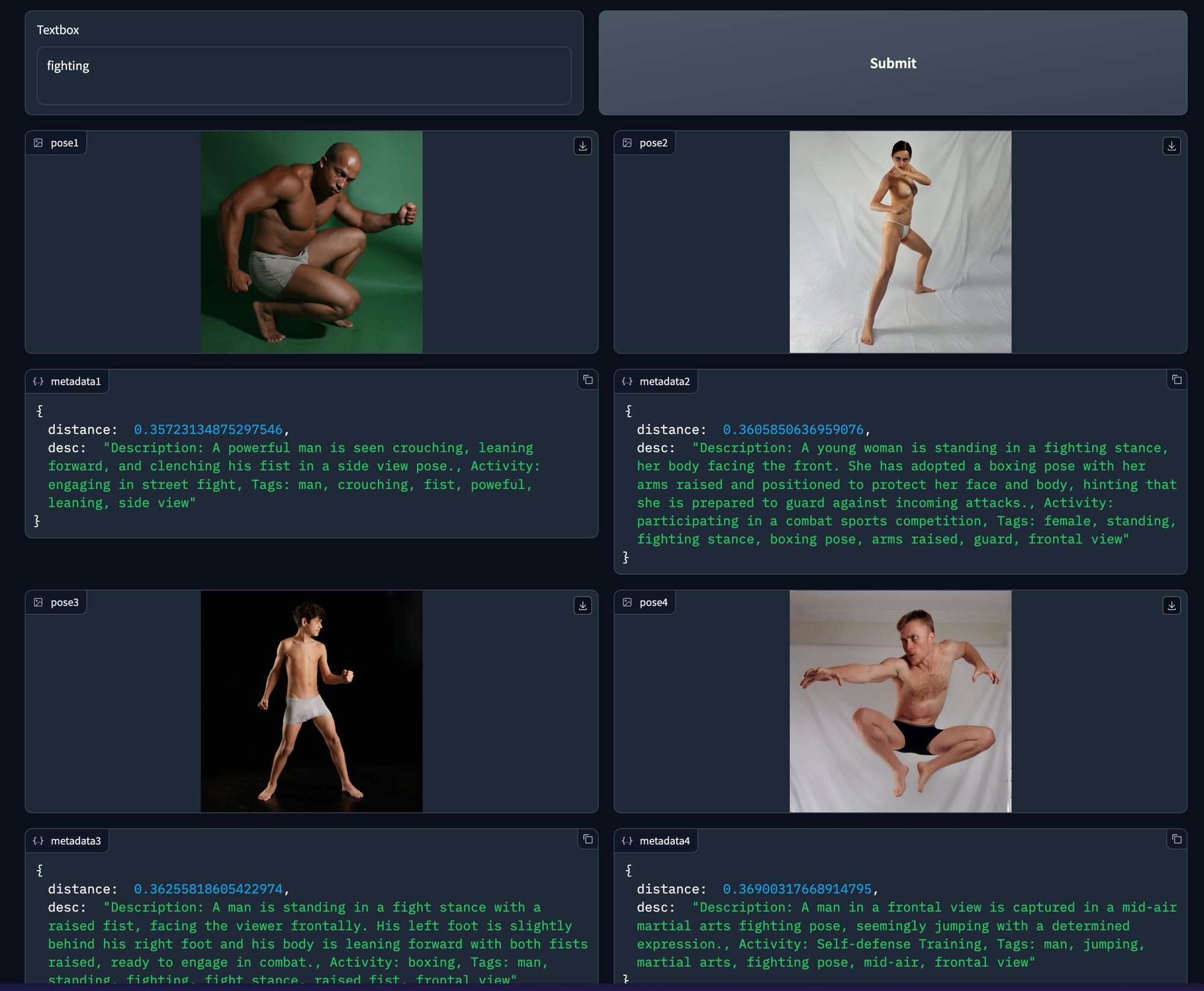
主要的挑战有两个
- 这样的数据集怎么生成呢?图片对应的那段文字描述是哪里来的?我难道要手动填写吗?
- 怎么把数据集中的图给取出来?
对于第一个问题,答案是当然不用!
我其实想到的最方便的方法是直接用支持多模态的模型,比如GPT-4或者Midjourney,用图片→文字(GPT4 API或者Midjourney Describe命令)转换。只不过GPT4暂时没开通多模态,Midjourney也没有API。所以在当下这个时间 May 2, 2023 ,我到底怎么才能让GPT4『看』到这些poses呢?
用OpenPose JSON!
比如这个姿势

我们可以很方便的提取OpenPose

而这个pose对应的JSON如下
我把这个JSON,和原始图片自带的一些Tags (很多图库都会自带一些Tags,当然你也可以自己再加一些进去),一起喂给GPT-4,于是就可以从GPT4那里批量生产关于这个pose的准确的描述。你甚至可以让GPT同时给你几个推荐的对应活动,这样能让后面做retrieve的时候抓得更准确。
比如这个是我得到的一个结果:
第二个挑战是获取姿势Pose Retrieval
如果你最近用过一些GPT的工具,类似的方法你可能已经接触过了:那就是给文本内容做embeddings后存到vector store里。我这里用的Langchain集成的OpenAI Embeddings和Chroma本地存储和搜索,主要是数据规模不大。对于规模较大的数据集,也可以考虑用Pinecone等云端vector store。
结语
也许以后做预处理可能直接把图片丢给大模型,大模型直接能返回一个精准的描述,不过我相信本文的方法在当前这个过渡阶段还是能帮助到一些需要方便地获取controlnet姿势图片的读者。
- Author:Yucheng L
- URL:https://lyc.fyi/article/text-based-pose-retrieval
- Copyright:All articles in this blog, except for special statements, adopt BY-NC-SA agreement. Please indicate the source!